Configuring Error Handling
Configuring error handling allows you to define the behavior when an execution fails. The main reason for implementing error handling is to prevent waiting tasks from starting when a prerequisite task fails.
For example, a sequence of Data Processing tasks representing a part of a life cycle of a transaction:
- Enter transaction
- Accept to FINAL
- Early expire
If step 1 fails, step 2 and 3 will also fail and don’t have to be started.
Error handling is configured per node (task, group, test case) in the test plan Error Handling column, with the available options Stop, Continue and Default, where Default means use the Stop/Continue default setting of the node type.
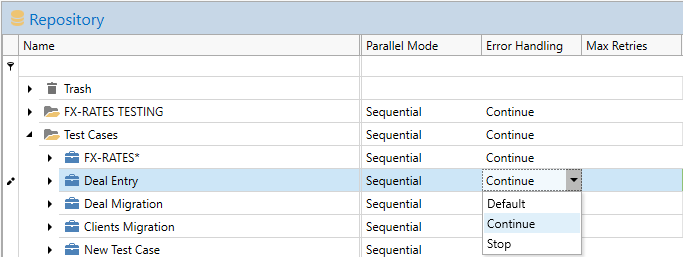
Error handling of tasks
It is important to note that a task that fails will always stop running, the setting Stop/Continue defines what happens with the rest of the running sequence. Tasks that explicitly depend on other tasks, i.e. uses the output of another task, will fail unconditionally if the dependency task fails. Error handling configuration is important for implicit dependencies, where the dependency is defined only in the order of tasks.
Consider the example of entering a transaction and expiring it. The test case consists of three Data Processing tasks that implicitly depend on each other in a sequence:

Failing to enter a transaction it won’t be possible to accept nor expire it, so for step “1. Enter transaction” we can configure error handling to Stop, which will stop the sequence if an error occurs in the first step.
The same logic can be applied to step 2. Looking only at these three steps alone, it seems OK to continue if step 3 fails since it is the last step in this unit.
Configure Error Handling to Stop for tasks that are critical to the rest of the sequence and Continue for tasks that are not.
Retrying tasks
Sometimes tasks are affected by temporary conditions that cause the operation to fail. This can be related to infrastructure upgrades, restarts of the underlying data source and many other factors.
Instead of failing tasks you can configure them to retry a number of times before reverting to the configured error handling behavior (Stop/Continue).
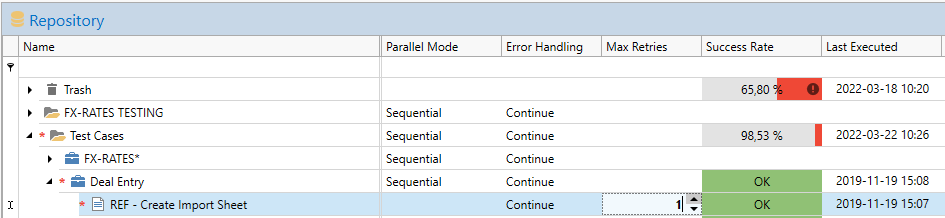
The condition for retrying the task is that it has failed. This is the same conditions as those to invoke the error handler (Stop or Continue):
- Success Rate less than 100%
or
- An error is reported in the Error column
It can be tempting to add a couple of retries just for good measure when configuring a task. While all tasks except Manual Task is eligible for retry, you need to consider if it is safe and sensible to use it:
- Data Processing tasks have side effects. Retried tasks don't pick up from when they failed, they start again from the beginning, so any side effect like entered transactions may be doubled in the target system.
- Report tasks can be designed with side effects, so carefully consider when you can safely use retry.
- Reconciliation tasks with Success Rate less than 100% have identified deviations in the data, and retrying will only identify the same deviations again. It makes very little sense to configure retry for reconciliation tasks.
Error handling of folders
Folder (group and test cases) nodes do not execute themselves and cannot fail by themselves. A folder node fails when one of its sub-nodes configured with Error Handling=Stop fails. A folder that fails because it receives and error from one of its sub-nodes will immediately stop all its sub-nodes from executing, but similarly to tasks the Stop/Continue setting defines if the sequence in which the folder executes should be stopped or continued.
Considering the early-expire example again in a little bit larger context:

- When “A. Early Expire -> 1. Enter transaction” fails it will cause the test case “A. Early Expire” to fail, since the task has Error Handling = Stop.
- Since the two test cases are logically separate “A. Early Expire” is configured with Error Handling = Continue.
Test cases that are independent and standalone (e.g. typical Unit Tests) can often be configured with Continue as the mode.
Configuring error handling defaults
Default error handling is configured in Settings -> Execution -> Error Handling Defaults.
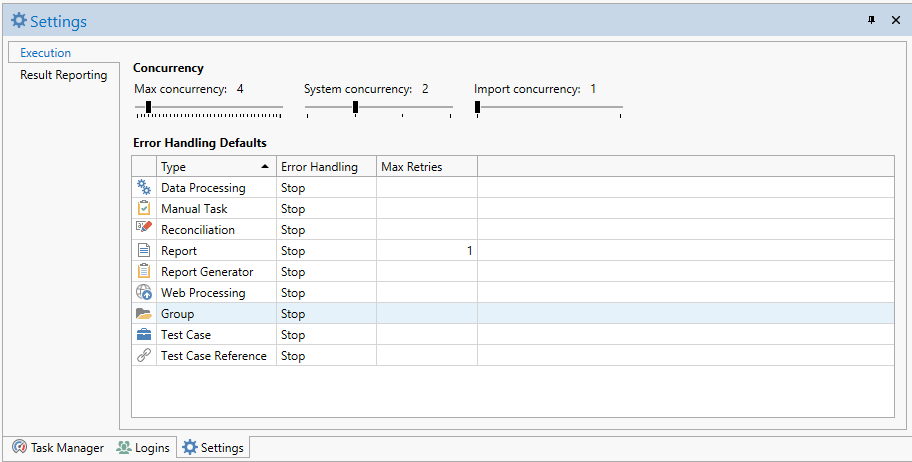
The default settings allow you to configure default behavior per node type. The default setting will be used by any node in the test plan where Error Handling is set to Default.
You can also set default values for Max Retry of tasks, but note that whether retry can be safely used without side effects should be carefully considered individually per task, not per task type.
Updated about 1 year ago