Scheduling Endpoints
Custom API endpoints can be scheduled to populate them with fresh data with regular intervals. Snapshot endpoints can’t be executed by end users, and scheduling is the only way to populate a snapshot with data. It is also useful to populate function endpoint with data before it is requested, as a mean to ensure optimal performance of the request.
In the Access page, select the endpoint you want to schedule and click the Schedule button.
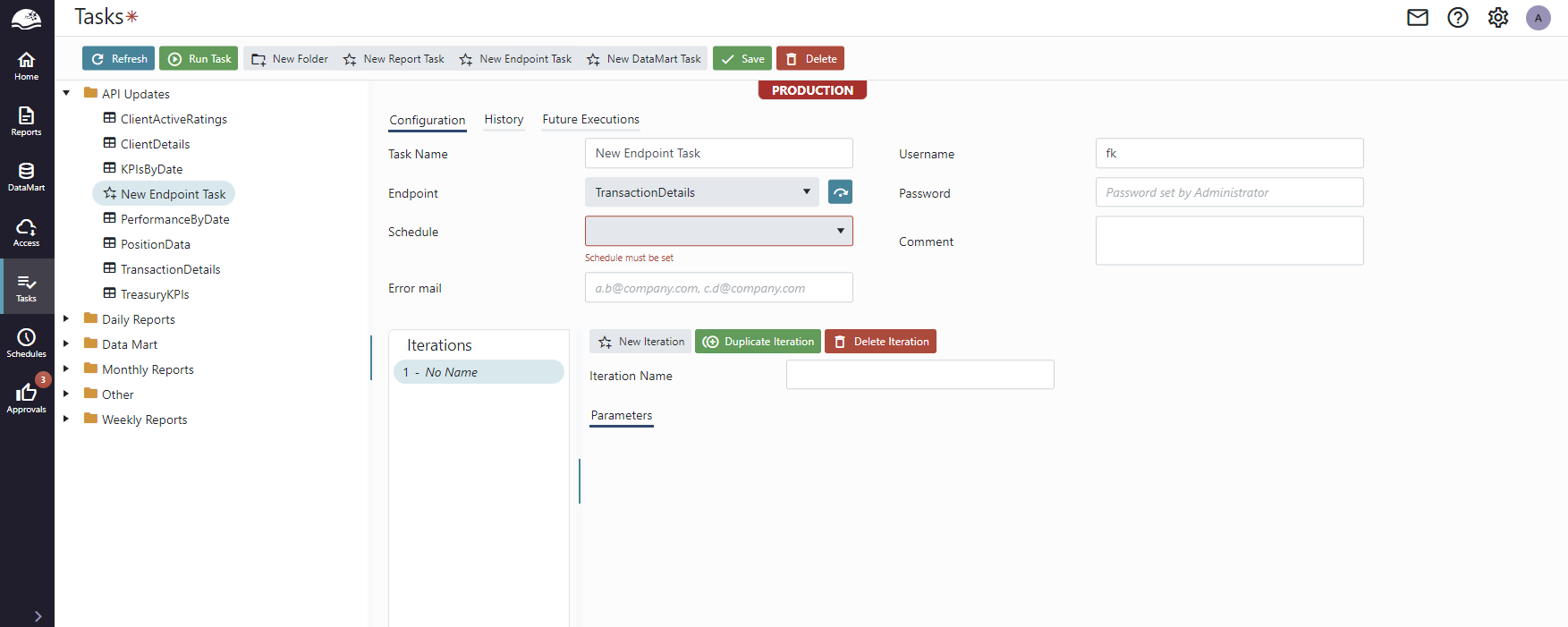
On the Task page, provide a name for the task and select an appropriate schedule, and if needed, iterations, parameter, executing user and error email.
Task login
The login is used to execute the underlying source. By default, the login of the creating user is used, but you can also configure this manually.
For function endpoints, the executing user (whether executing as a task or via the API) is used as a part of the identity of the cached data. Only the user login configured for the task will have access to the cached data using the API. If you want to publish to multiple users, use snapshot endpoints instead of function endpoints.
Snapshot endpoints do not use the executing user as part of the identity of the cached data. Instead, data is published data globally to anyone who has access to the endpoint. If you want to publish different data individually to different users or user groups, configure multiple snapshots with different permissions, or use function endpoints instead.
Iterations
The Iterations section lets you select what parameters to run the endpoint with. All parameters accepted by the endpoint are presented on each row. Adding additional iterations (rows) will have the endpoint run once per iteration, with different parameters.
Iterating over function endpoints
Configuring iterations over function endpoint will create one cache set for every iteration. API requests to a function endpoint requires the full set of parameters of the endpoint as input, meaning it can match only one of the iterations.
Iterating over snapshot endpoints
Iterations over snapshots work slightly differently. As there are no parameters accessible over the API, the result of each iteration is concatenated into one large result. In this case, configuring multiple iterations is very useful to iterate over, for example, a series of portfolios or timespans that would be too large to handle in one single iteration.
Iterating over import endpoints
Iterations over import endpoints treat the iterations as individual parameter sets in a batch import operation.
Formulas
Instead of assigning a static value, it is possible to assign a formula to calculate the value when the task is executed. Formulas start with ‘=’, followed by an expression, e.g. =1+1. It is possible to reference particular pre-defined variables from a formula, e.g. =["Due Date"], assigning the task due date as a value to a parameter.
Available variables are:
- ["Due Date"]
- ["Start Date"]
- ["Endpoint Name"]
- ["Task Name"]
- ["Endpoint ID"]
- ["Task ID"]
There are many built-in functions available, as well as relevant arithmetic and logical operators. (Please refer to the Report Modifiers for additional details)
Updated about 1 year ago