Model configuration
Models are created from report datasets in the OmniFi Web portal. A Data Mart Report is no different compared to a regular OmniFi Web Report.
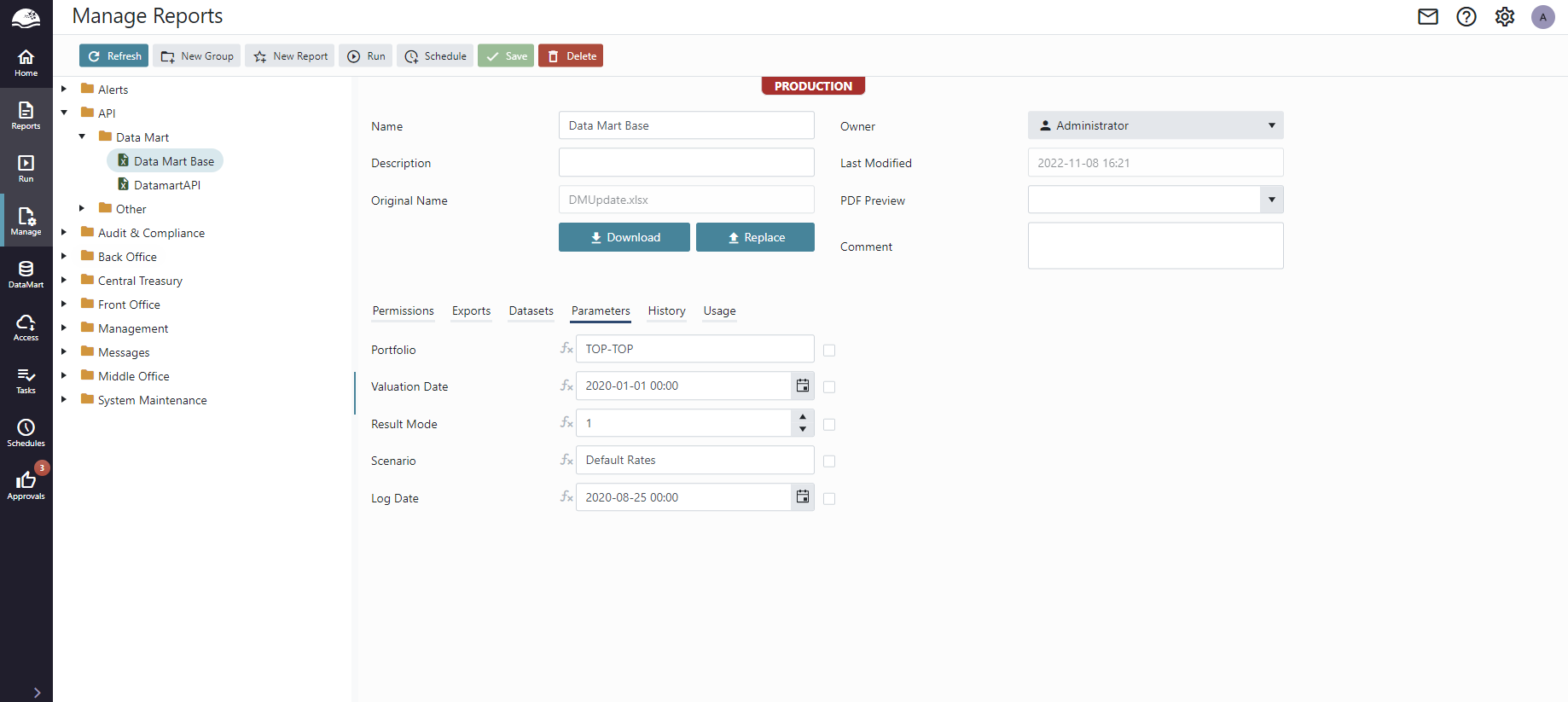
Creating & managing Models
A new model is created from the Data Mart Models page using the "New Model" button.
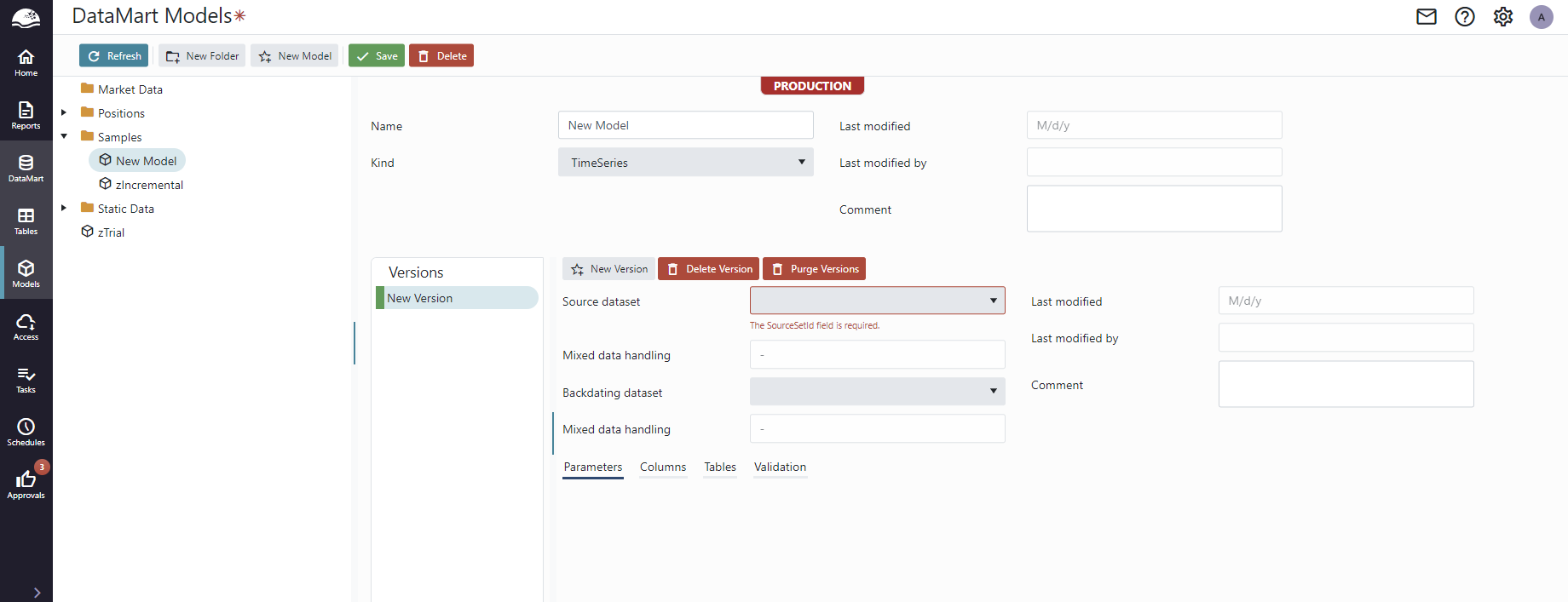
Select a name, the appropriate data set from your report and the model Principle. In the case of Time Series also backdating set is configurable.
The Principle cannot be changed after creating the model, so be careful to select the correct one. Please see Principles for additional information.
Version handling
Data Mart models are version-handled.
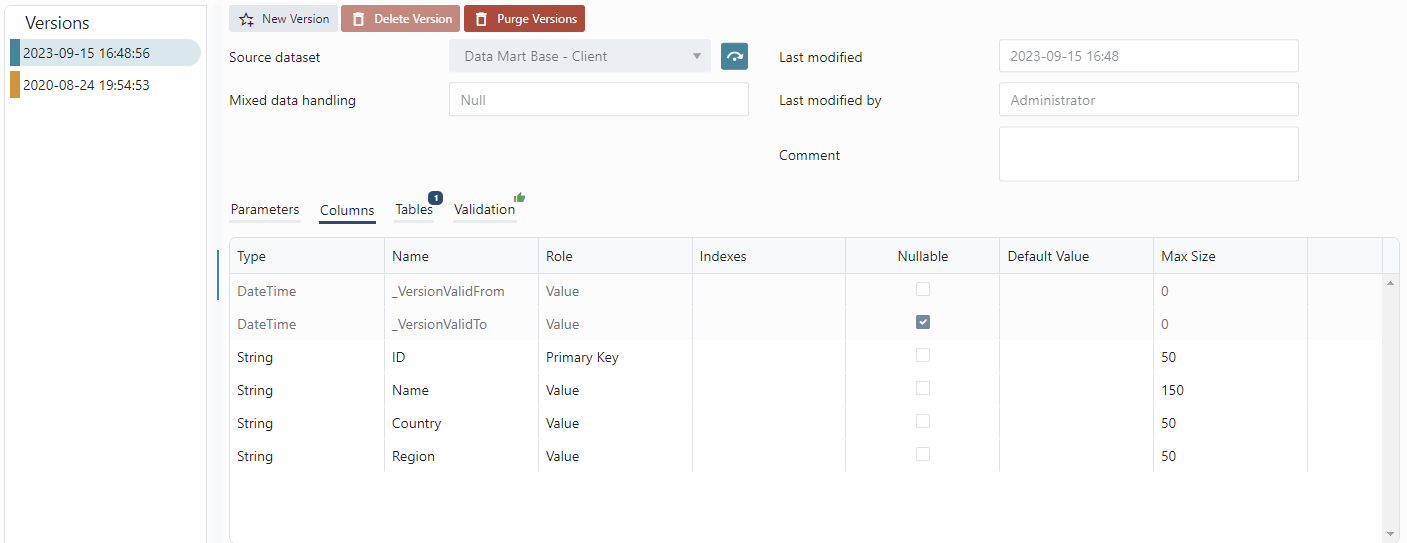
The version name is a timestamp of when it was first created, providing a time-line of changes. There is also a Comment field to document important changes in the version, or for mnemonic notes.
The versions are always linear. Unlike version handling systems like SVN or Git, there are no branches or merges.
The colored blocks display the status of the version,
- Green - OK, unused
- Blue - Used by a table
- Orange - Has validation errors.
A version linked to one or more tables is locked for editing. Creating a new version of the deployed model provides a safe way to continue working on the configuration. Since tables can be deployed in different schemas, you can create a new version of a deployed model, modify it and deploy the new version in a separate schema for testing before migrating the production table to the new version.
The models page allows you to edit the currently displayed version (if not deployed), and to create a new version as a copy of the current version.
Note that the Save button saves all edits to all versions, not just the one currently displayed.
Principle
Each model is configured with a principle that governs the basic behavior of the model and defines the basic anatomy of any table based on the model.
The available principles are Time Series, Slowly Changing and Incremental.
Time Series
Time Series is used to define a time series fact table with a new snapshot of the data on each time increment. This allows time series and trend analysis to be performed and is arguably one of the main reasons to invest in a data mart solution to begin with.
Time series are commonly used to implement fact tables containing operational data and supports backdating. See Backdating for more information about backdating.
Slowly Changing
Slowly Changing is used to define a version-handled dimension table containing a snapshot of a slowly changing entity, typically static data. The main benefit with this principle is that it is version handled, which makes it possible to "go back in time" and view the data precisely as it was on a prior date. This is especially useful when joining with a time-series fact, allowing you to view both the facts and the dimension precisely as they were at a point in history, and for example to maintain an additional audit trail of changes to sensitive data like accounts.
Incremental
Incremental is the simplest principle, simply appending data to a table. The principle isn't version handled, and because of that it provides its own automatic key column and doesn't require configuration of primary keys.
| Principle | Version Handled | Primary Key | Parameters | Load |
|---|---|---|---|---|
| Time Series | Yes | Required | Allowed | Merge |
| Slowly Changing | Yes | Required | Allowed | Merge |
| Incremental | No | Not allowed (uses automatic ID column) | Not allowed, all parameter values must be provided in the model configuration. | Append |
Columns
The Columns tab configures various details regarding how the report columns are translated into table columns.
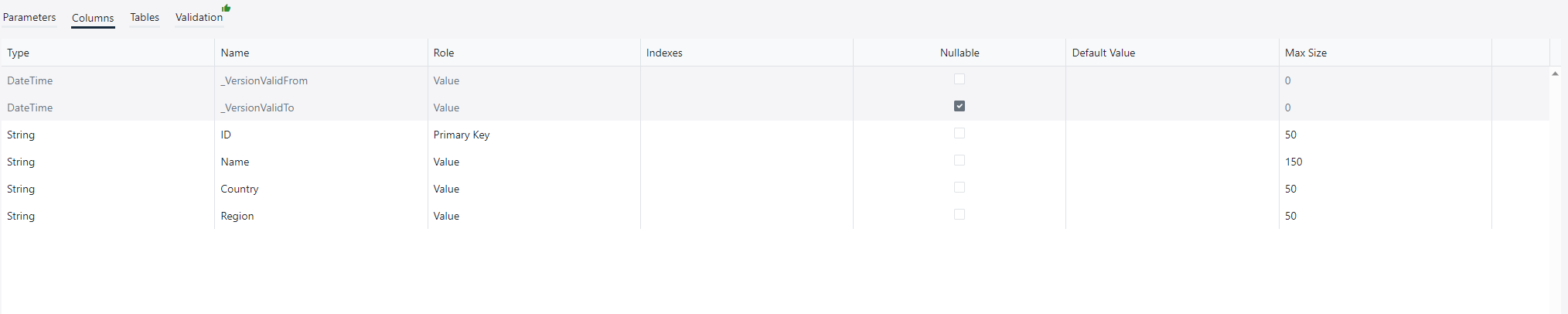
- Type displays the data type of the report column.
- Name displays the descriptive name of the report column. This is also used as name of the column in the database table.
- Role The role of the column within the table. Please see section Column roles for more details.
- Indexes allows you to configure database indexes on the column. Please see section Indexes for more details on configuring indexes.
- Allow Null determines if the data table column is nullable or not. Please see section Nullable and defaulted columns for more details.
- Default Value sets a default value for the column when adding it in a table migration, or when the ETL pipeline inserts null values. The value is in SQL server format, i.e. a string is formatted N'text' etc. You can also give SQL functions as a default value.
- Max Size is used to determine the maximum size of string and binary columns. Set this to -1 to allow nvarchar(max)/varbinary(max). If the value is set to 0, OmniFi will ignore it and the data type used is the database default.
Column roles
Each column is configured with a value defining its role in the table:
- Figure Date describes the time dimension of a time series and added to the primary key of the data table. It is not allowed on Slowly Changing and Incremental models.
- Primary Key columns are used as primary key in the data table, together with the Figure Date and parameter open columns. The Primary Key role is not allowed on Incremental models, which creates a separate AutoId column as primary key.
- Value columns are common data columns without specific role.
Nullable and defaulted columns
When adding a column to an existing table, the new column needs to be initialized for all the existing records in the table, and for nullable columns, the null value is prioritized:
| Column | Nullable | Not Nullable |
|---|---|---|
| Default value | NULL | DEFAULT |
| No default value | NULL | FAIL |
When the ETL pipeline feeds a null value to a column the situation is slightly different, the default value is prioritized:
| Column | Nullable | Not nullable |
|---|---|---|
| Default value | DEFAULT | DEFAULT |
| No default value | NULL | FAIL |
Default values are entered directly in SQL format depending on the data type used.
| Data Type | Example | Comment |
|---|---|---|
| String | N'text' | Text values are entered on the form N'<text>' |
| Int | 12345 | |
| Double | 123.45 | Decimal values use '.' as decimal point by default. |
| Boolean | 'TRUE' | Booleans are entered as quoted values. The casing of the value may depend on your collation. |
| DateTime | '2020-12-31 20:00:00.000' | Date time values are entered quoted in an ISO-like 24h format 'yyyy-MM-dd hh:00:00.fff'. Note that the precision may be truncated. '2020-01-01' is allowed. |
| Any | getdate() | Columns of any data type allow you to enter SQL functions such as getdate() as default values. |
Indexes
Indexes are created in the Columns section Index field. The Index field accepts input on the form index_name[([order=n], [isunique=true|false])].
You can only create non-clustered indexes. Clustered implies sorted, and the table is clustered according to the primary key.
Index can span over multiple columns, and the same column can be included in multiple indexes. When an index spans multiple columns, the order is important. The order using the order=n argument determines the order of the column in the index. If the order argument is omitted, the index will be ordered by the order in which the columns appear in the user interface.
A column can be included in an arbitrary number of indexes by entering a comma separated list of index specifications for the column, as in the example of the D column in the example in the table below.
| Column | Indexes | Description |
|---|---|---|
| A | IX_a | A non-cluster index, non-unique index is created over column A. |
| B | IX_bcd | A non-cluster index, non-unique index is created over column B and C. |
| C | IX_bcd | A non-cluster index, non-unique index is created over column B and C. |
| D | IX_d(isunique=true), IX_bcd | A non-clustered unique index is created over column D. D is also included in the index IX_bcd |
| E | IX_feg(order=1, isunique=true) | A non-clustered unique index is created over columns F, E and G. |
| F | IX_feg(order=0, isunique=true) | A non-clustered unique index is created over columns F, E and G. |
| G | IX_feg(order=2, isunique=true) | A non-clustered unique index is created over columns F, E and G. |
Effective use of indexing can substantially improve query performance, however, indexes also consume space and since INSERT operations must update all indexes, excessive use of indexing will decrease the load performance. OmniFi Data Mart automatically creates a clustered index over the entire primary key, including parameter and Figure Date columns, and in many cases, this is enough.
Additional indexing should mainly be configured if you have observed slow query performance, or if you are certain beforehand what the common query scenarios will be.
Parameters
Most reports will require a set of input parameters at runtime to execute.
The model details page section Parameters allow you to configure values for some or all report parameters directly on the model, meaning they cannot be set at runtime. The parameter values are configured design-time and "closed" by the model.
Parameters for which values are not provided on the model are "open". Values for open parameters need to be supplied runtime, i.e. as task parameters for the scheduled task that executes the ETL pipeline.
Open parameters are automatically translated to columns in the table, and displayed grayed out along with other auto-generated columns.

The parameter columns are populated with the runtime parameter value when the ETL pipeline executes and are automatically included in the primary key of the table, allowing multiple separate sets to be loaded into the same table.
Another way of thinking about this is that the data can be loaded in segments into the table. The parameter column represents an "ID" for the segment, and the primary key configured on the model represents a unique identifier within the segment. This way the MERGE load statement can only load data within the segment identified by the parameter columns.
- If the primary key in the loaded data doesn't exist in the table segment, the record is added to the table.
- If a primary key from the table segment doesn't exist in the loaded data, the record is deleted from the table.
- If the primary key exists both in the table segment and the loaded data but with different values in the value columns, the record is updated.
The parameter columns allow this operation to be performed on a segment of the table. If a primary key exists in a different segment in the table than the one identified by the parameters, it is completely disregarded by the current load operation.
The primary key on a database table is not easily changed. Since open parameters are included as primary key in the table, the choice of closing a parameter and excluding it from the key or to leave it open needs to be carefully considered.
Validation
The model configuration is validated when the model is saved, and the result is displayed in the Validation tab.



The mismatching data set validation error is fixed automatically if you create a new version. The new version will automatically use the latest data set definitions.
When you update to the newest version of the report, the Parameters and Columns section will load the new definitions and merge with your current configuration. Depending on what changes have been made to the underlying report, the Columns and Parameters configuration may have to be manually amended.
The changes will not take effect until you actively Save the model.
Backdating
Time series models support backdating.
Backdating occurs when an operational event changes after inception, causing valuations and historical figures to change. Time series are also version handled, allowing you to compare time increments before and after backdating.
Backdating is configured on a time series model by selecting a backdating set.
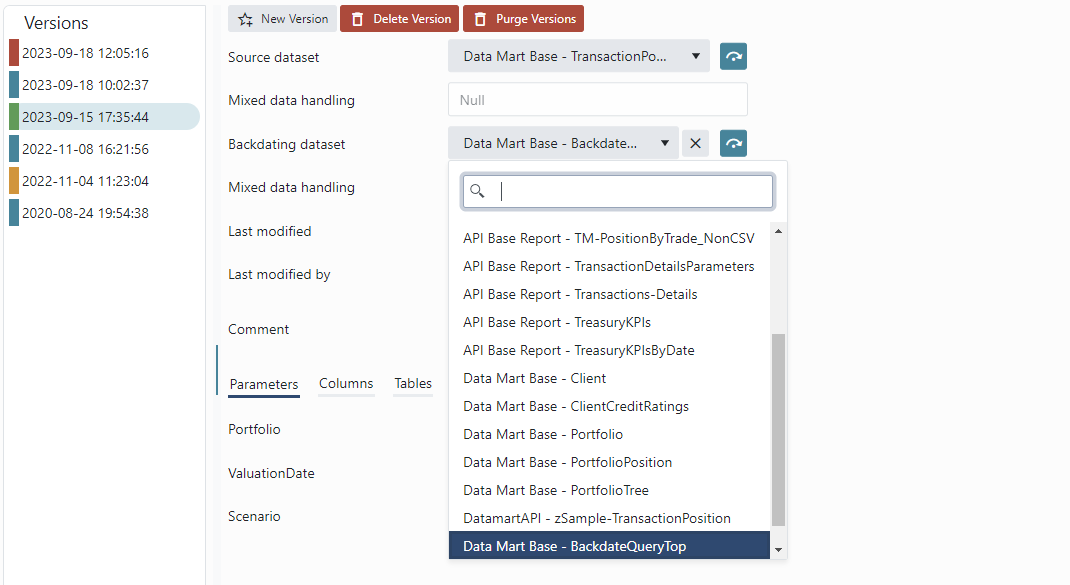
When running the ETL pipeline in backdating mode, the backdating set is first executed. The output of the backdating set will be the parameters for which the source dataset is executed for. If a transaction for example is backdated for three days, then generally the backdating set will return which three days the execution needs to rerun for.
The output columns from the backdating set are mapped to open parameters of the model by column description and data type. Both name and data type must match exactly, and values must be provided for all open parameters.
Additional columns in the backdating output are ignored. The raw output from the backdating run is saved for auditability, so additional information describing the origin of each row can be included as extra columns in the backdating report.
Updated 4 months ago