Custom APIs
The custom data API publishes report datasets and Data Processing operations over web API endpoints, making the data available externally using HTTP GET and POST.
To publish a custom data endpoint:
- Upload a report workbook to the web portal.
- Configure datasets from the workbook that can be used for the API.
- Create an endpoint.
- Configure permissions for the endpoint.
Note that this page discusses how to configure and publish Function, Snapshot and Import endpoints, as these all work in a similar way. For more information on table endpoints, please refer to Table APIs
Uploading report workbook
Any report workbook uploaded to the Web portal can be used as the basis for the API. Please refer to Uploading Reports for more details on how to upload a report workbook.
Configure Datasets
Each report in a workbook provides a dataset which can be viewed in the Datasets tab on the Manage Reports page.

Report with several available datasets
Only enabled datasets can be used by API endpoints. When a workbook is uploaded to the portal, all valid report datasets are enabled by default, but you can enable/disable datasets per report workbook manually.
Datasets that are invalid will be marked as such and the Validation error column will provide an explanation why the dataset is invalid. The most common reason is that no column mode has been configured in Report Editor by setting “Null” or “Error” in “Mixed Data Handling”.
Endpoint configuration
Endpoints are configured on the Access page.

Access page
The Access page lists are current endpoints and lets you create, modify and delete endpoints. You can also view the result and download output of the latest execution.
Endpoints are placed into a group structure similar to how files are stored in folders. The group structure is administered centrally, and only permitted users can create, delete and modify groups. Where in the group structure an endpoint belongs is, however, decided by the endpoint creator.
Click the New Endpoint button to create a new endpoint.
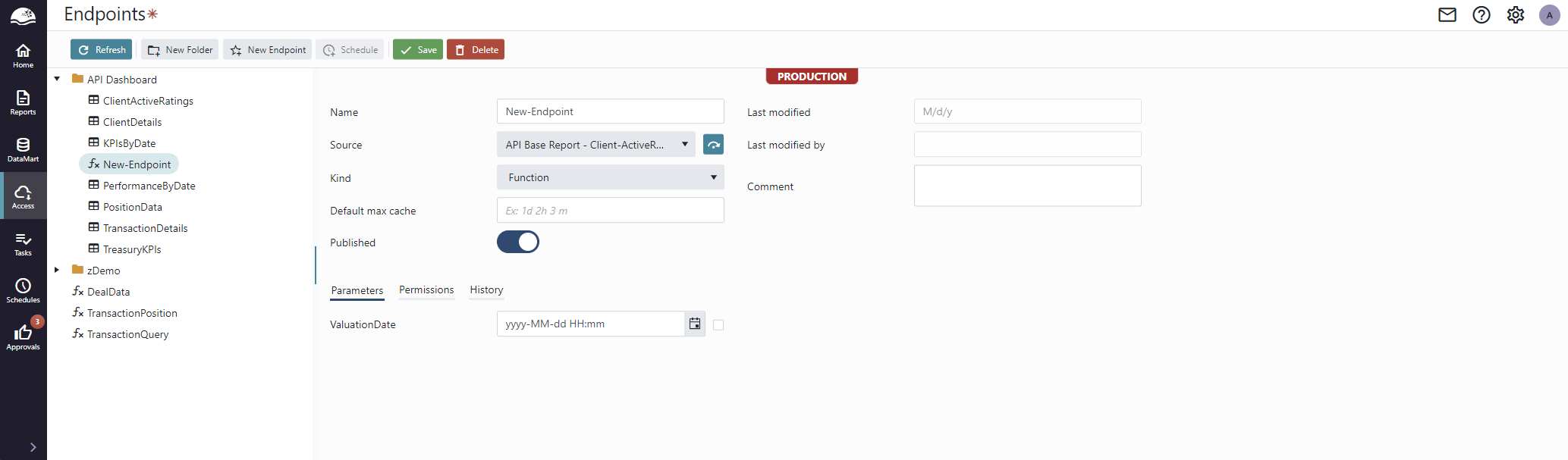
Set a unique name and selected a data set to create new endpoint. This will take you to the Endpoint Details page, where all other settings can be set.
| Field | Comment |
|---|---|
| Name | Unique friendly name of the endpoint by which API users will access the endpoint. Restricted to upper- and lower- case letters, digits and underscore (‘_’). |
| Source | Source dataset that provides data to this endpoint. |
| Kind | There are three kinds of endpoints, Functions, Snapshots and Imports. |
| Publish | The endpoint is only made available in the API if it is published. This allows you to configure an endpoint fully before publishing it to the API by checking the Publish checkbox. |
| Default max cache time | This determines the default maximum cache time for this endpoint. The default value will be used if “MaxAge” is not set in the request to this endpoint. The format is “Xd Yh Zm”, where d = days, h = hours, m = minutes. E.g. for cached data to be valid for an hour, enter “1h”. |
| Last Modified | Timestamp for the last modification of the endpoint configuration. |
| Last Modified By | Name of the user who last modified the endpoint. |
| Comment | User provided comment. |
Parameters
When publishing an endpoint, you have the option to provide parameter values for some or all of the parameters.
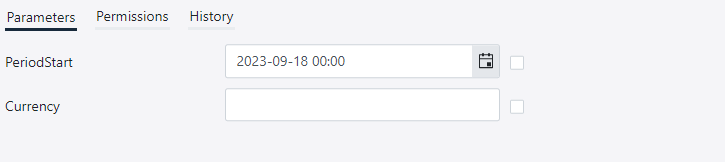
Open parameters (with no configured value) are mandatory to provide when using the API endpoint. In the case of snapshot endpoints, the scheduled task must provide values for all open parameters. The checkbox next to each parameter can be used to make the parameter optional.
| Value | Checkbox | Description |
|---|---|---|
| Not configured | Unchecked | The parameter value must be provided when using the API endpoint. |
| Configured | Unchecked | A parameter value cannot be provided when using the API endpoint. |
| Configured | Checked | The parameter value can optionally be provided when using the API endpoint. |
Permissions
Permissions to access the endpoint using the API is configured per endpoint.

Users (or groups) assigned Read permission can read snapshot. Users (or groups) assigned Execute permission can execute functions and imports.
Service Header
The service header configuration is available for Import endpoints and corresponds to the service header supplied with Data Processing import sheets.

Example service header configuration
To configure the service headers, copy the service header from your Excel prototype and paste into the paste box. The headers will be parsed automatically.
Data Cache
The API maintains a data cache per Function and Snapshot endpoint to optimize performance and minimize load on the underlying data sources. When an endpoint has been executed, the resulting data is placed in the cache for fast access, and any subsequent requests for the same data will be serviced from the cache. Each endpoint, user and set of endpoint parameters is a unique cache item:
- For function endpoints the cache will be used if the request is from the same login user and with the same parameters.
- For snapshot endpoints the cache will always be used. If there is no cached data, a 501 response is returned.
When configuring an endpoint you must consider and balance the need for access to fresh data with the need for fast access and minimizing load on the underlying data sources by selecting appropriate endpoint Kind and Cache Valid Time.
Data API
The Data API is accessible from the URL <Service URL>/api/data. The OmniFi API infrastructure supports several different data formats including Json, XML CSV and Bson. It is possible to select a format is done by appending an extension after the endpoint name, e.g:
<Service URL>/api/data/Clients.csv<Service URL>/api/data/Clients.json<Service URL>/api/data/Clients.xml<Service URL>/api/data/Clients.bson
Bson is binary-json, a format used in some document databases. It is more light-weight than Json and should be preferred where the client tool can interpret Bson.
CSV is lightweight and easy to read both manually and by machine, however it doesn’t retain data type information; all data is text. Many tools, including MS Power BI and Excel can automatically interpret CSV data into typed data if given a hint as to how the file is localized.
To facilitate this, the API supports adding a Culture argument when requesting CSV data.
<Service URL>/api/data/Clients.csv?Culture=en-US
Will return a CSV response in US English format, including number format, date format and list separator.
<Service URL>/api/data/Clients.csv?Culture=sv-SE
Will return a CSV response in Swedish format, including number format, date format and list separator.
Asynchronous calls
Import endpoints support asynchronous (sync) calls. While synchronous calls return when the requested operation has finished, async calls return very quickly, while the operation is still running in the background. The execution can be monitored and result retrieved using a GET operation on a forward location. This is highly useful to call long running operations, and avoids the risk of running into HTTP timeouts.
An import endpoint published under the name CREATE-FX-SWAP will have a synchronous endpoint CREATE-FX-SWAP and an asynchronous counterpart CREATE-FX-SWAP-async.
To use the async endpoint:

Sequence diagram describing usage of async pattern
- Make a POST request to
CREATE-FX-SWAP-asyncwith the appropriate parameters in the request body.- The endpoint will respond quickly with a 202 and forward in the Location response header.
- Monitor the execution by making repeated GET requests to the forward location:
- OmniFi Access will respond with the result code 202 Accepted for as long as the execution is still ongoing.
- When the execution is finished or failed the result code changes to 200 OK. The OmniFi-Result and OmniFi-Error response headers contain success or failed information. (OmniFi-Error is only included if OmniFi-Result Failed).
OData API
The OData API is accessible from the URL <Service URL>/api/odata and uses a Json-based transport format.
The main benefit of OData vs REST is that OData enabled clients have access to metadata and can present a richer parameterized UI. It also has many features for filtering, sorting and limiting data already on the remote server side rather than transport the whole dataset over the network and process it locally.
Ex: OData request fetching all records from some Transactions endpoint where nominal amount is larger than 1000 000:
<Service URL>/api/odata/Transactions?$filter=nominal_amount gt 1000000
Ex: OData request fetching all records from some Transactions endpoint where nominal amount is larger than 1000 000 and ordering by opening date:
<Service URL>/api/odata/Transactions?$filter=nominal_amount gt 1000000&$orderby=opening_date
OData is powerful, please refer to the OData v4 documentation for complete documentation of abilities.
The OmniFi API infrastructure supports the operations $filter, $orderby, $top and $count.
Updated about 1 year ago